Share this
by Bridget.Giacinto on Jun 4, 2015 3:52:24 PM
Data is growing exponentially and along with it, the storage requirements to house that data. Data duplication, (means of reducing redundant data) is one way companies are reducing their raw data size and thus their storage costs. Repeated, duplicate data is a problem that all companies face, whether they realize it or not. The options for addressing that duplication, vary greatly in terms of cost, CPU/ memory usage, and storage savings.
If you are using Windows Server 2012, you already have access to a free data deduplication tool. You may not even realize it (as many users are still not aware of this feature), but deduplication is a native feature offered within Windows Server 2012, so it will NOT cost you any additional money to deploy. While Microsoft included this option, they did not enable it by default. As the Windows Server 2012 operating system is now approaching 3 years on the market, we thought it was time to discuss this deduplication option and how to enable it, as well as the types of deduplication available and what deduplication can do to help reduce your storage costs concerning your backup destination.
 Data Deduplication can Reduce Storage Costs.
Data Deduplication can Reduce Storage Costs.
What is data deduplication?
Any discussion about data deduplication should start with an understanding of what it is. Data deduplication is the technology that is used to find and remove duplicate data to reduce redundancy, backup storage space requirements, and costs.
There are two primary software-based methods for data deduplication, inline and post-process.
- Inline Deduplication: This type of deduplication uses software to remove any redundancy in the data before it reaches its final storage destination. The system responsible for sending the data also carries the workload in terms of CPU and memory resource usage. Inline deduplication comes at a cost of speed, in that it often results in significantly slower data transfer speeds to the backup destination device.
- Post-processing Deduplication: This type of deduplication is faster in that it backs up all of the data and sends it first to the backup destination (resulting in a shorter backup window), and then it checks the storage blocks to see if they are duplicates. Initially, this option requires more storage space, although this is temporary as duplicate data blocks are discarded.
Since it’s important to consider where the data is being deduplicated, we should take a closer look at source vs. target-based data deduplication.
- Source-Based Deduplication: This type of deduplication takes place at the “source” on the same file systems that the data originated – usually at the server or application level.
- Target-Based Deduplication: This type of deduplication takes place at the “target” location where the data is being copied, such as the backup storage destination.
Before I get into how to enable and use the deduplication feature available within Windows Server 2012 and 2012 R2, we should take a quick look at how the data is deduplicated because it makes a difference in terms of the overall amount of reduction achieved and the time each approach takes to determine what is and is not unique. There are 3 primary methods that we will look at file, block, and chuck-based deduplication.
- File-Based Deduplication: This type of deduplication takes place at the “file” level, meaning that each file is looked at to determine if they are the same. If the file already exists a duplication of that file is not stored, rather it simply points to the original file. However, if that file ever changes, that deduplication is broken and the space savings are lost. File-based deduplication uses fewer resources, but it also does not provide a lot of savings in terms of storage space.
- Block-Based Deduplication: This type of deduplication takes place at a sub-file level, in that the file is broken down into segments or blocks, that are then examined for redundancy as compared to previously stored information. Fixed block-based deduplication offers fast dedup, with a decent deduplication rate, but it does not come without any downfalls. For example, if a single byte of data changes within that block of data, the entire block cannot be deduplicated. To address this, block sizes are often relatively small, and while this reduces the overhead of wasted space, it does require longer processing time.
- Chunk-Based Deduplication: This type of deduplication, also called variable block-sized deduplication helps to increase the likelihood that a common segment will be identified, even if a file is modified. The method is similar to block-based deduplication, except instead of fixed blocks, it uses algorithms to determine natural variable-length breakpoints that might occur in a file and segments the data accordingly. While these chunks of data may vary and shift to allow for a higher deduplication rate and thus reduce data storage space requirements, it does require more processing time.
Windows Server 2012 Data Deduplication
Now that you have a better understanding of the different data deduplication methodologies, let’s take a look at which methods Microsoft has selected for their native data deduplication for Server 2012 and 2012 R2.
Microsoft has opted for post-processing, source, chunk-based variable block deduplication. This means that the data is first transferred to the destination device before doing the data deduplication to reduce the size of the data using the chunking variable-length method to get the best possible data deduplication rate. This means that there will be less CPU and memory usage required to transfer the files to the destination device, which is a good thing because it means it will not slow down your production server. But, on the flip side, you will also need to make sure you have enough storage available to handle the data from your backup on the storage destination as the deduplication will happen there.
Deduplication Setup in Server 2012 (R2)
Before you can start using the deduplication feature within Server 2012 (R2), you will need to install and configure it. To do so, open the Server Manager and select the Add Roles and Features option in the Manage Menu. Continue through the wizard until you get to the Server Roles screen. You will need to select the Data Deduplication Role (Installed) by first opening up the file tree for File and Storage Services (Installed) and then File and iSCSI Services (Installed). From there, just click Next on the remaining screens until you can click Install.
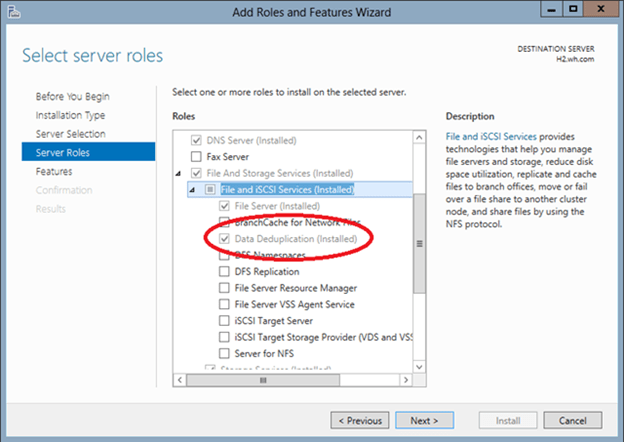
In order to do deduplication, you will need to configure it on a per-volume basis. To do so, right-click on the volume and select Configure Data Deduplication.
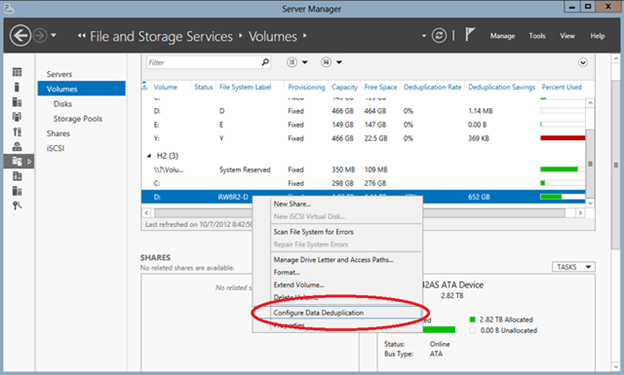
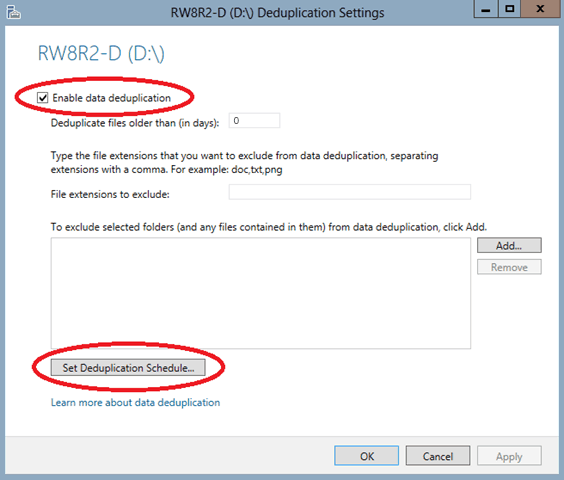
Then simply check the Enable Data Deduplication box. If you are planning on utilizing the volume you just configured as storage for your backups, I would recommend setting the Deduplicated files older than (in days) to 0, so that when your optimization jobs run they grab all of your files. If you want to save system resources, you can change this to a higher number to make sure that a file is a few days old before deduplicating it, but for backups specifically, this isn’t recommended.
Next select Set Deduplication Schedule….
This is the step where you enable the background optimization and throughput optimization by checking these boxes. If you are using this storage device for backup storage purposes, which is likely to transfer at night, I would recommend changing the default schedule. Thankfully, you have the option to set up two separate schedules for throughput optimization.
Based on the feedback from our tech team, I would recommend setting up your first optimization job early in the morning when backup jobs should be done and a second one that finishes right before your nightly backup jobs kick-off.
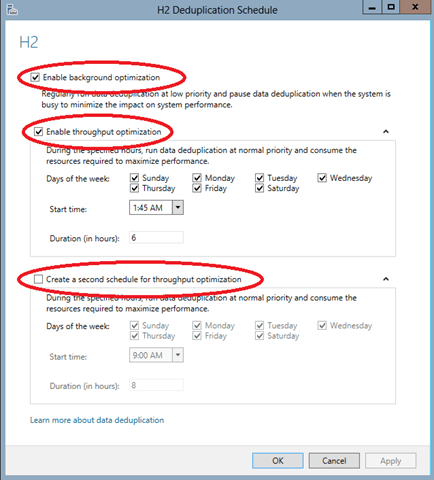
Make sure to schedule both optimization and garbage collection jobs. Garbage collection and scrubbing should normally be setup just once a week, but depending on your data size and how often things are deleted on your volume you might want to adjust that to fit your needs. By default, data deduplication creates a weekly data integrity scrubbing job, but you can also trigger one on demand using the code below. Garbage collection jobs process previously deleted or overwritten data chucks to create usable free space on the volume, but it is a processing-intensive operation so it should be scheduled or run manually demand during off hours.
You can deploy Scrubbing on demand in PowerShell with the following code:
Start-DedupJob E: –Type Scrubbing -full
Scrubbing jobs output a summary report in the Windows event log located here:
Event Viewer\Applications and Services Logs\Microsoft\Windows\Deduplication\Scrubbing
You can also deploy Garbage collection jobs on demand by typing the following command in PowerShell:
Start-DedupJob E: –Type GarbageCollection -full
Setup in NovaBACKUP
If you are planning on utilizing NovaBACKUP for the backup software to back up to your newly created deduped volume, there is a couple things that I would recommend in order to get the best deduplication performance. First, you will want to disable compression for your backup jobs. Since we are going to be utilizing deduplication to reduce the amount of data stored, we want the data in a format that doesn’t completely change with every backup. You can do this in the settings of your backup job.
Within NovaBACKUP, select the Backup tab, and click Settings at the bottom of the screen to view the Advanced Settings. From here you can click the Backup tab and uncheck the box for Compress backup files.
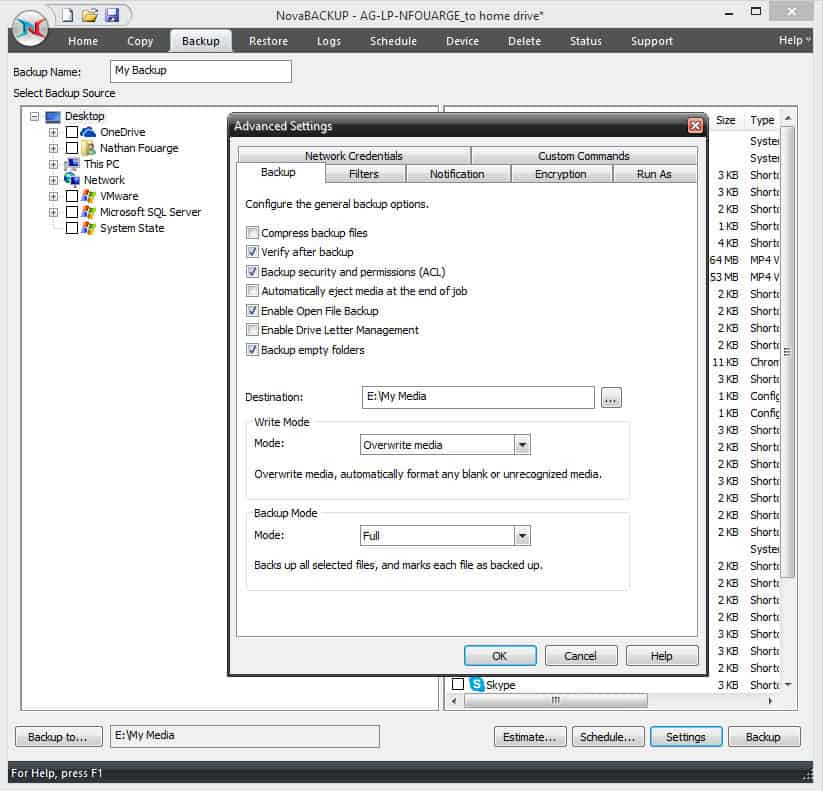
To get the best deduplication rate, the other thing you may want to consider is not encrypting your backup job. While the rationale for this is the same as compression, in this case, you will need to weigh the risk of not having your backup encrypted versus getting a better deduplication rate. This feature is also found under Settings on the Encryption tab. By default encryption is set to none, so you will need to enable this if you would like to create encrypt your backups with a user-created password.
Other than that, there isn't anything else you need to do within NovaBACKUP to back up to a deduplicated volume, either Server 2012 (R2) deduplicated volume or other deduplicated volumes that you might have available.
For more information about NovaBACKUP, click here.
Share this
